


- Nvidia nabízí možnost spouštění velkých jazykových modelů lokálně na vašich počítačích
- Využívá k tomu program LM Studio a techniku GPU offloading
- Díky tomu můžete na svém notebooku spouštět i modely, které vyžadují mnohonásobně více paměti
Umělá inteligence, nebo spíše konkrétněji velké jazykové modely (LLM – large language models), jsou v současné době tématem číslo jedna, minimálně v oblasti technologií. Běžný uživatel k nim přistupuje skrze různé služby třetích stran, jako je ChatGPT, Gemini, Apple Intelligence či Copilot. Až na výjimky ale většina z nich funguje prostřednictvím cloudu, což má řadu výhod, ale také pořádný seznam nevýhod, především pokud jde o bezpečnost. Naštěstí existuje ucelené řešení od Nvidie, které vám umožní využívat všech výhod LLM pohodlně přímo z vašeho stolního počítače či notebooku.
ℹ️ Stačí jeden klik! Přidejte si nás mezi mezi preferované weby, případně nás sledujte v Google Zprávách, nebo na Seznam.cz
LLM nemusí běžet jen v datových centrech
Velké jazykové modely od základu mění a především zvyšují naši produktivitu. Umí například vytvářet návrhy dokumentů, shrnout vše podstatné z webových stránek či přesně odpovídat na celou řadu otázek, pokud je takový model trénován na velkém množství dat. LLM jsou základem řady moderních služeb, které pro zjednodušení označujeme jako umělá inteligence – konkrétně sem spadá například generativní AI, digitální asistenti, konverzační avataři nebo také roboti vyřizující dotazy zákazníků na technické podpoře.
I když většina běžně dostupných AI využívá možností cloudu, dnes už není problém provozovat LLM také lokálně na počítačích a pracovních stanicích. Díky tomu můžete jistotu, že vaše konverzace a veškerý obsah je pod vaší kontrolou. Navíc také využijete výkon grafických karet Nvidia GeForce RTX, které toho mimo hraní náročných her či využívání náročných programů v počítačích povětšinou moc na práci nemají. Ostatní modely bohužel kvůli své komplexnosti často postrádají video paměť na grafických kartách a je potřeba využít hardware ve velkých data centrech.
Nicméně je zde možnost část promptů zadat lokálně na počítačích s grafikami RTX díky technice zvané GPU offloading. Ta umožňuje využít akceleraci GPU bez toho, aniž by byl uživatel limitován pamětí konkrétní karty. Je ovšem potřeba mít stále na paměti, že je zde korelace mezi velikostí modelu, kvalitou odpovědí a rychlostí, s jakou vám model na dotaz odpoví. Obecně platí, že velké modely poskytují přesnější odpovědi, avšak zpracování dotazu je pomalejší. Pochopitelně to platí i obráceně, kdy menší modely jsou výrazně rychlejší, ale jejich odpovědi nemusí být vždy přesné. Vždy přitom záleží na tom, co preferujete – pro některé případy, jako generování obsahu, nemusí být delší čas na odpověď překážkou, kdežto u konverzačních botů není žádoucí, aby byli nepřesní.
LM Studio: rozběhněte LLM i na svém počítači
Tady se dostáváme k programu LM Studio (zdarma ke stažení zde), který uživatelům umožní stáhnout a mít na svém počítači funkční LLM. Tento nástroj je navíc jednoduchý na ovládání a nabízí řadu možností přizpůsobení. LM Studio je postavené na softwarové knihovně llama.cpp, tudíž je plně optimalizováno s použitím grafických karet GeForce RTX a grafik postavených na architektuře Nvidia RTX. Spojení programu LM Studio a techniky označované jako GPU offloading nabízí výhody navýšení výkonu při využívání lokálního LLM, i když model nemůže být zcela nahrán do VRAM (grafické paměti).
S GPU offloading může LM Studio rozdělit model na menší části, které reprezentují vrstvy architektury daného modelu. Tyto části nejsou permanentně nahrány na GPU, ale přesouvají se sem podle potřeby. V rámci LM Studio si sami uživatelé mohou vybrat, kolik těchto vrstev bude jejich grafika zpracovávat.
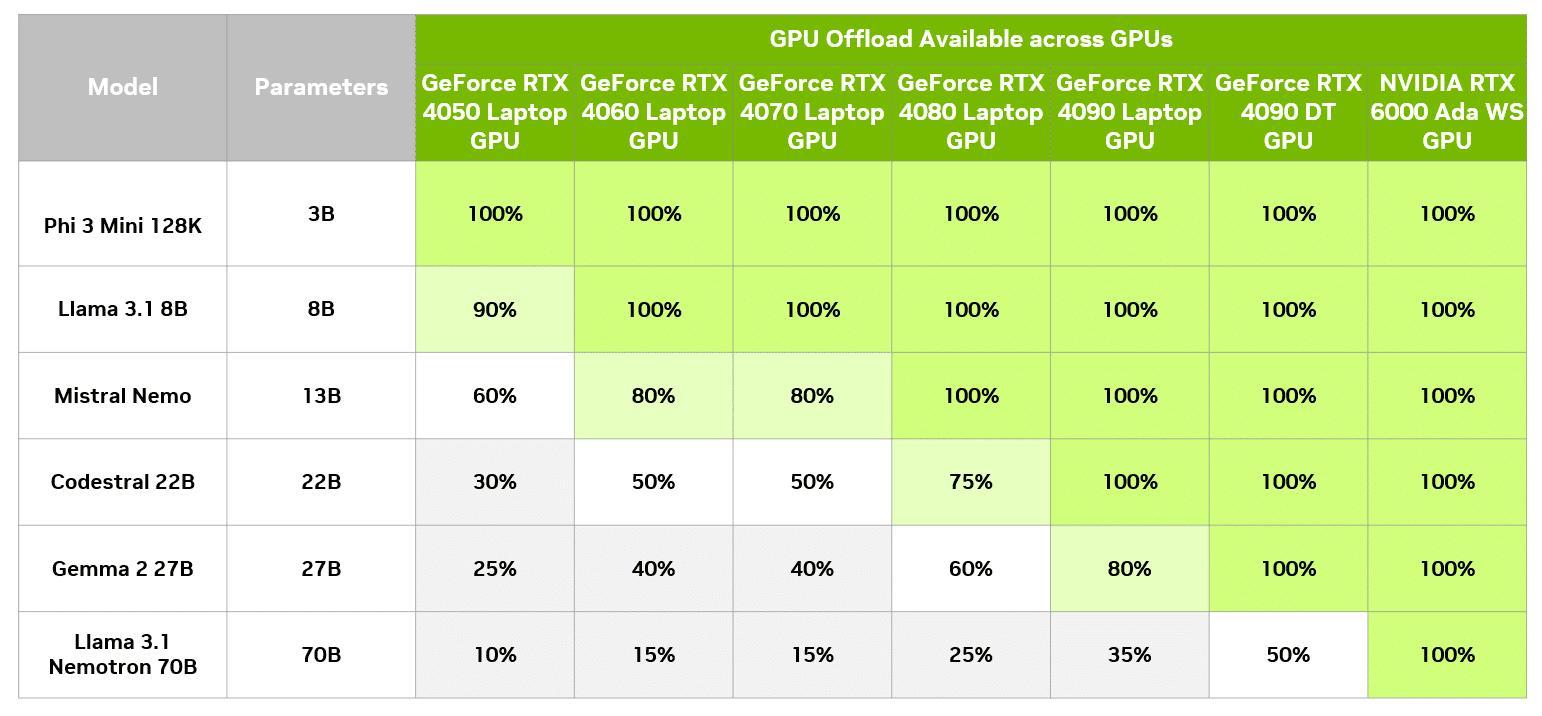
Kupříkladu si představte model Gemma 2 27B, kde segment 27B označuje počet parametrů v rámci modelu, které naznačují, kolik paměti bude potřeba pro jeho spuštění. Podle 4-bitové kvantizace, tedy techniky redukující velikost LLM bez výrazného vlivu na přesnost, každý parametr zabere půl bytu paměti. To znamená, že model by měl potřebovat 13,5 miliardy bytů, či 13,5 GB, plus něco málo navíc. Akcelerace tohoto modelu čistě na grafice by vyžadovala 19 GB VRAM, která je k dispozici na plnohodnotné grafické kartě GeForce RTX 4090. S GPU offloading může tento model běžet i na nižších grafických kartách bez výrazného zpomalení.

V LM Studio je možné vyhodnotit dopad různých úrovní na výkon GPU offloadingu. V rámci tohoto konkrétního modelu si uživatelé s 8GB GPU mohou užít rozumnou rychlost oproti tomu, když by tento model spouštěli pouze na CPU. Pochopitelně karty s 8 GB VRAM mohou spouštět menší modely, které se do paměti vlezou kompletně, a využít tak naplno akceleraci GPU. Jinými slovy je GPU offloading programu LM Studio užitečný nástroj pro odemknutí plného potenciálu LLM, která jsou navržena pro datová centra a díky této funkci mohou běžet lokálně přímo u vás na počítači.
Nvidia hledí také do budoucnosti
Tím ale Nvidia nekončí. Na veletrhu CES v Las Vegas technologický gigant odhalil nové základní modely AI, které budou distribuovány jako mikroslužby Nvidia NIM. Ty využívají možnosti nových grafických karet z řady GeForce RTX 50, jež jsou postaveny na architektuře Nvidia Blackwell. Díky tomu tyto karty nabídnou výkon až 3,352 bilionu AI operací za sekundu, 32 GB VRAM a v rukávu mají také funkci FP4, jež zdvojnásobuje výkon AI a umožňuje generativní AI běžet lokálně bez nutnosti využití velkého množství paměti.
Mimoto se Nvidia pochlubila s řešením AI Blueprints – předkonfigurovanými pracovními postupy připravenými k okamžitému použití, které jsou postaveny na výše zmíněné službě Nvidia NIM a využít je lze například pro vytváření obsahu či digitálních osob. Mezi prvními modely, jež mohou uživatelé využívat, jsou ty z rodiny Llama Nemotron. Jedná se o otevřené modely s vysokou přesností, které mohou provádět celou řadu úkolů. Kupříkladu Llama Nemotron Nano, který bude nabízen skrze mikroslužby NIM na počítačích a pracovních stanicích s RTX AI, exceluje v AI úkolech, jako je následování instrukcí, telefonování, chatování, kódování či matematika.
Michael Chrobok
Další dnešní články






