


Žijeme v moderní době, kdy na zpověď místo ke knězi většina lidí chodí na Facebook, tam pak s přáteli či širokou veřejností sdílí veselé i smutné příhody ze života. Nejpopulárnější sociální síť se během několika let rozšířila po celé zeměkouli jako epidemie a s tím se zároveň začala šířit i řada výstražných článků o tom, jakým způsobem Facebook nakládá s vámi sdíleným obsahem například i po zrušení účtu nebo jak si přivlastňuje autorská práva k vámi nahraným fotografiím. Do toho ale zabředávat nebudeme, dnes probereme zajímavý způsob jakým Facebook díky umělé inteligenci automaticky detekuje obsah vašich fotek, k čemu tyto informace používá a jak si je můžete i vy zobrazit.
ℹ️ Stačí jeden klik! Přidejte si nás mezi mezi preferované weby, případně nás sledujte v Google Zprávách, nebo na Seznam.cz

Facebook moc dobře umí rozpoznat obsah fotografie
Bill Gates se kdysi nechal slyšet, že rád zadává složité projekty líným lidem, protože ti najdou vždy chytrý způsob jak odvést zadaný úkol a zároveň se ušetřit od hodin či dnů úmorné práce; například napsáním jednoduchého programu či skriptu, který automatizuje jinak rutinní a nudnou práci. Ve velice zjednodušeném pojetí právě takto funguje moderní průmysl – už v 19. století se začala lidská síla nahrazovat roboty, kteří vykonávají v sériové výrobě jednoduché opakované úkony místo lidí rychleji, přesněji a bez přestávky na oběd, odpočinek či cigaretu.
Stejně tak když si musíte ve škole či v práci opsat nějaký dokument, tak to nebudete dělat po staru ručně, ale dokument si vyfotíte, chytrá aplikace vám fotografii zanalyzuje a převede do textového dokumentu, se kterým můžete téměř ihned dále pracovat. Vyhledávat informace v textu a vyhodnocovat taková data je dnes hračka a umí to hromada programů. O něco větší oříšek je ale detekovat ne-textový obsah z grafiky či fotografie.
Facebook právě nad tímto úkolem pracoval 10 měsíců, a to proto, aby pomohl nevidomým a jinak zrakově postiženým. Těm dnešní chytré telefony dokážou přečíst text z obrazovky, tedy například status na Facebooku nebo komentáře pod fotografií, ale bohužel až dosud nemohli zjistit co je na obrázku, který jejich přátelé komentují.
Dle slov tvůrců tohoto algoritmu nebylo ani tolik těžké detekovat co se nachází na fotografii, jako spíše rozlišit co je na ní nejzajímavější nebo nejzásadnější; v jednom případě to může být nějaká osoba či její výraz, v druhém zachycená činnost jako třeba běh či jízda na kole, ve třetím případě může být nejpodstatnější naopak pozadí za vyfoceným člověkem – například na fotografii níže je podstatné, že náš šéfredaktor Jirka nestojí před samoobsluhou v Kačerově, ale v italských Alpách, což lze snadno zjistit, když nahlédnete do zdrojového kódu, kde najdete klíčová slova.

Tento algoritmus funguje v podstatě podobně jako kognitivní funkce lidského mozku, kterému naše rodiče od malička ukazují předměty, barvy, obrázky nebo lidi a přiřazují jim názvy a jména, v mozku se pak vytvoří vazba mezi smyslovým vjemem a naučeným názvem. S tím souvisí například i relativita barev – jednak je každý může vnímat trochu jinak kvůli anatomickým odlišnostem a jednak červená barva je pro vás červená jenom proto, že vám to řekli rodiče a jim jejich rodiče, ale nebudeme odbočovat.
Podobným způsobem i Facebook přiřadí ke svému skriptu obrovskou databázi barev, lidských výrazů a ukázkových předmětů, pomocí kterých jej „naučí“ co je strom, jakou barvu má tráva nebo jak poznat lidský úsměv. Pak vámi nahranou fotografii porovnává s touto databází vzorových obrázků a napíše pokud možno nejpřesnější odhad v lidsky znějící formě, například „obrázek může obsahovat: 1 osoba, stojící, usmívající se, v horách“.
Vyzkoušejte si to na svých fotografiích
Vzhledem k neskutečné variabilitě fotografií nahrávaných na Facebook se autoři této funkce prozatím v první verzi omezili na 100 tématických konceptů. Patří mezi ně lidský vzhled (např. dítě/dospělý, brýle, vousy, úsměv, šperky), příroda (hory, sníh, nebe), doprava (auto, loď, letadlo, kolo), sporty (tenis, plavání, stadión, baseball) a jídlo (zmrzlina, pizza, dezert, káva). Dále se snaží popsat okolnosti snímku jako počet lidí, předměty na něm (budova, strom, mraky, jídlo), zda je pořízen v interiéru, či v exteriéru a další vlastnosti jako text na fotografii nebo zda jde o selfie.
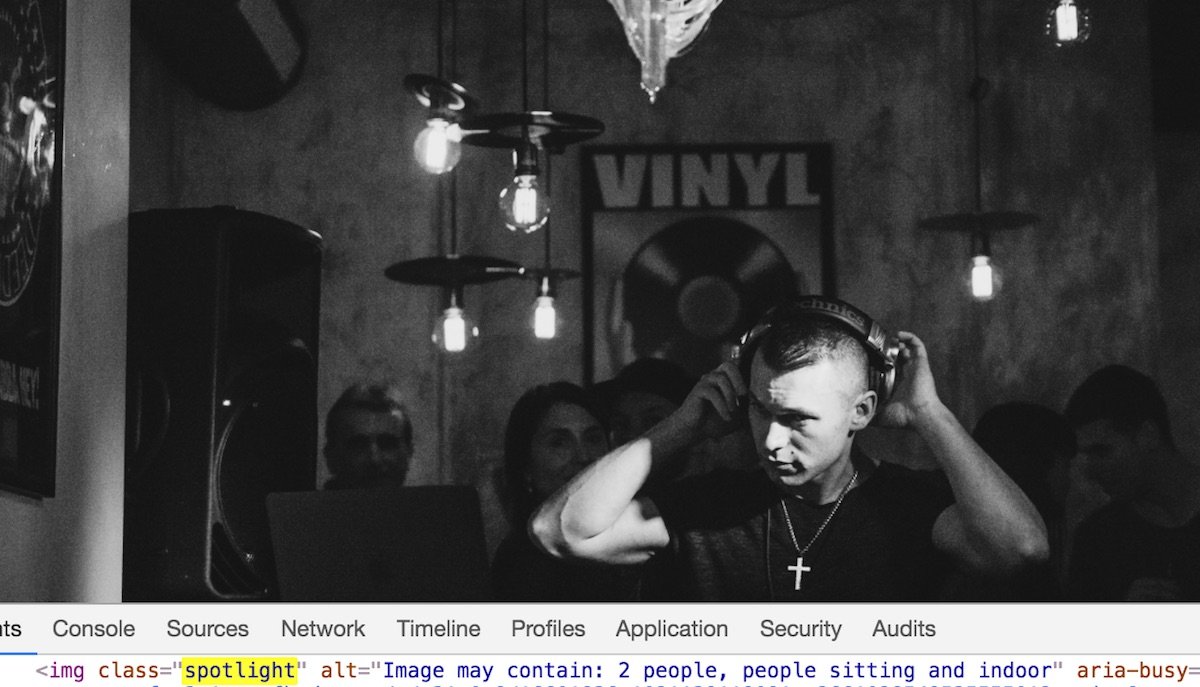
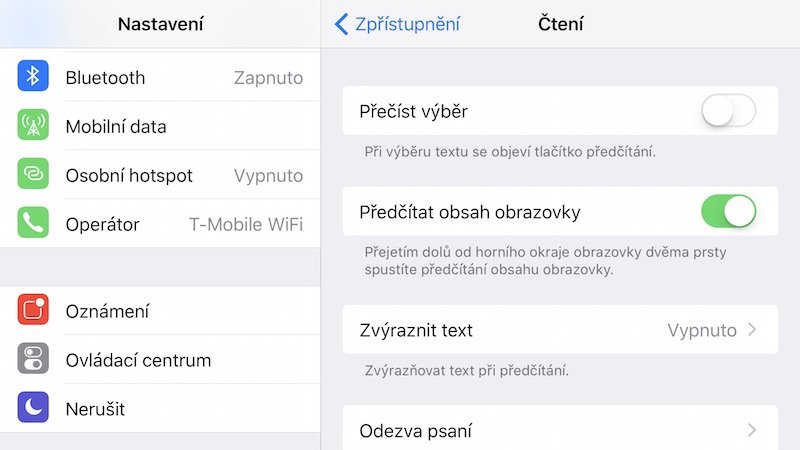
Jak jsem již zmínil výše v textu – tento projekt je teprve v začátcích, takže se tým programátorů snaží stále pracovat na zpřesnění automatických odhadů a důležitá je pro ně i zpětná vazba od uživatelů sítě. Služba je prozatím dostupná pochopitelně jen v angličtině a jen ve Spojených Státech, Kanadě, Británii, Austrálii a na Novém Zélandě pro uživatele iOS, kteří na svém telefonu aktivují v možnostech zpřístupnění předčítání obsahu obrazovky; telefon pak bude automaticky předčítat počítačově generované popisky obrázků v aplikaci Facebook.
Do budoucna je pak v plánu rozšířit nabídku i na jiné platformy, jazyky a země. Pokud se ale chcete pro zajímavost podívat jaké tagy přiřadil program k vašim fotografiím, stačí si otevřít na stolním počítači Safari nebo Chrome, kliknout pravým tlačítkem na fotografii a zvolit položku „Prozkoumat“; ve zdrojovém kódu si pak můžete přečíst vygenerovaný popisek s klíčovými slovy – stačí hledat výraz <img class=”spotlight”…







