


- DeepSeek V3 přináší revoluci v oblasti umělé inteligence díky otevřenému přístupu a mimořádné efektivitě tréninku
- Open-source model V3, vyvinutý s minimálními zdroji, konkuruje nejlepším uzavřeným systémům
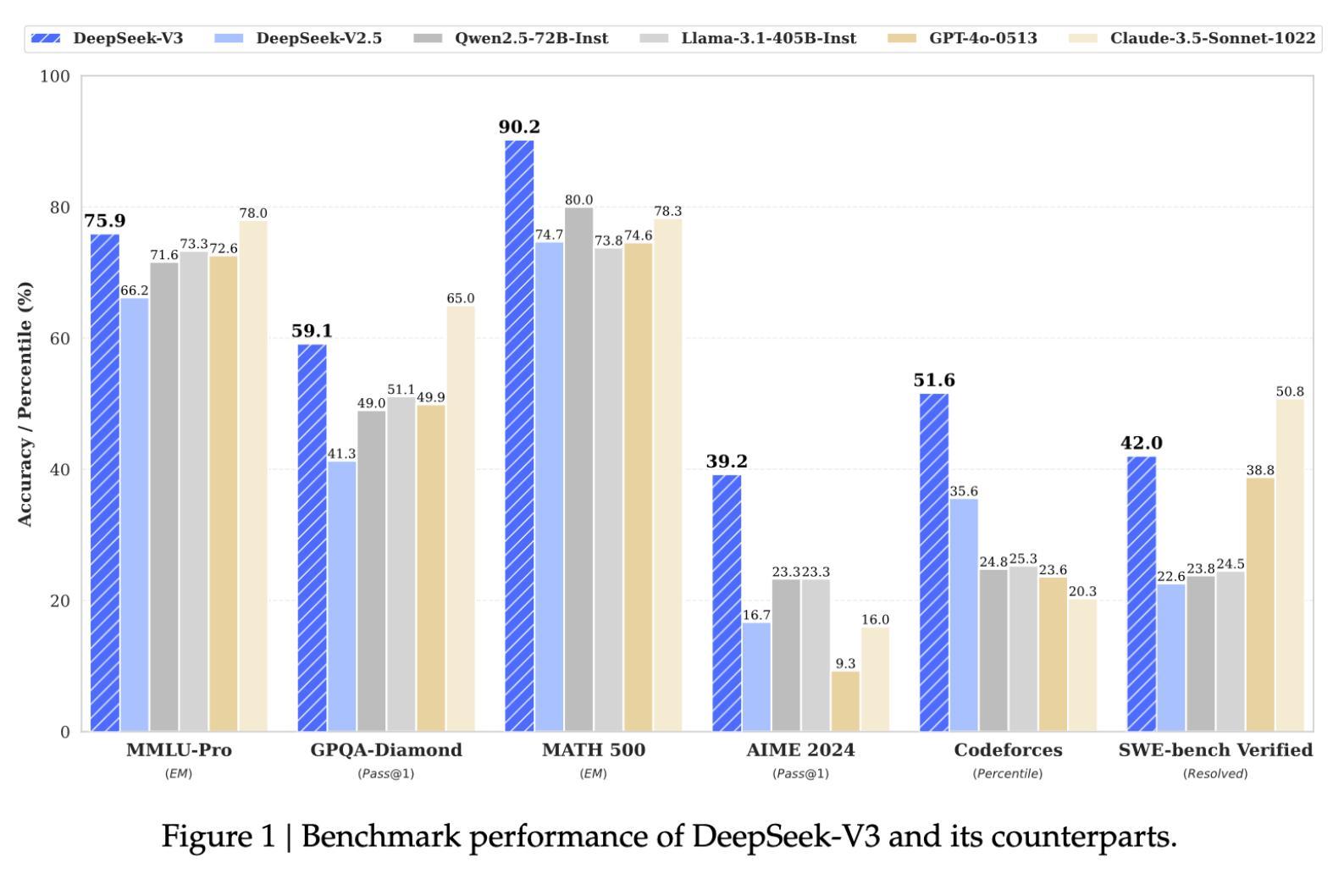
Společnost OpenAI minulý týden představila svůj nový model O3, nebo alespoň jeho ukázku, co dokáže. Debaty o tom, zda tento model může být označen za obecnou umělou inteligenci (AGI), nabírají na intenzitě. Nicméně dnešní příběh patří čínské společnosti DeepSeek a jejímu modelu DeepSeek V3, který dokázal s minimálními zdroji konkurovat těm nejlepším uzavřeným AI modelům na trhu.
ℹ️ Stačí jeden klik! Přidejte si nás mezi mezi preferované weby, případně nás sledujte v Google Zprávách, nebo na Seznam.cz
DeepSeek V3 je plně open-source, velmi rychlý a dokonce i levný na provoz. Co víc, své konkurenty překonává ve většině klíčových metrik. Jak to jeho tvůrci dokázali? Podívejme se na příběh, který stojí za vznikem tohoto modelu, a na jeho dopad na budoucnost umělé inteligence. Jde totiž o poměrně velkou věc.
DeepSeek V3: Minimální zdroje, maximální výsledky
Andrej Karpathy, významný odborník na AI, upozornil na klíčový fakt: DeepSeek dokázal vytrénovat svůj nejnovější model s použitím pouhých 2048 GPU za dva měsíce a s rozpočtem 6 milionů dolarů. Pro srovnání, obdobné modely často vyžadují clustery o velikosti 16 000 GPU nebo více a mnohem větší náklady. Výpočetní efektivita DeepSeek V3 je tedy násobně vyšší než u obdobných modelů.
Karpathy dále zdůrazňuje, že tato významná redukce výpočetní náročnosti přišla navzdory americkým omezením na export AI čipů do Číny. DeepSeek tak demonstruje, že omezení mohou být účinná jen částečně.
Otevřený přístup: příležitost, nebo hrozba?
DeepSeek V3 staví na principu otevřeného softwaru. To znamená, že kdokoliv s dostatečnými zdroji může tento model spustit lokálně nebo pomocí API. Tento otevřený přístup nejenže zpřístupňuje pokročilé AI technologie pro větší počet uživatelů, ale také dramaticky snižuje bariéry vstupu pro jednotlivce a menší organizace, které si nemohou dovolit drahé uzavřené modely, jako je GPT-4o nebo Claude 3.5 Sonnet.
Díky možnosti spouštět model lokálně nebo pomocí API se trénink vlastních modelů stal nejen jednodušším, ale hlavně dostupnějším. Firmy a jednotlivci nyní mohou modely přizpůsobit přímo svým potřebám – ať už jde o specifické datové sady, nebo funkce, které odpovídají jejich konkrétnímu oboru.
Tento otevřený přístup tak dává malým agilním firmám i jednotlivcům jedinečnou šanci konkurovat velkým korporacím. Zároveň podporuje demokratizaci vývoje AI a nabízí téměř bezprecedentní příležitosti k bezpečné implementaci AI do interních procesů i práce s citlivými daty. Tím se otevírají dveře nejen ke zjednodušení pracovních postupů, ale také k rychlejší inovaci napříč průmyslovými odvětvími.
Inovace v architektuře: Mixture of Experts
Jednou z klíčových inovací DeepSeek V3 je použití architektury Mixture of Experts (MOE). Místo jednoho velkého modelu, který by musel řešit všechny úkoly najednou, DeepSeek V3 využívá kolekci menších specializovaných modelů (tzv. expertů). Tyto expertní modely se aktivují pouze tehdy, když jsou skutečně potřeba, což dramaticky snižuje náklady na výpočet a zvyšuje efektivitu celého systému.
Představte si firmu, která má místo jednoho geniálního, ale přepracovaného zaměstnance několik odborníků, kteří jsou schopni spolupracovat a řešit úkoly efektivněji a levněji. Každý expert se věnuje své oblasti a společně tvoří tým, který zvládá úkoly rychleji a s menším úsilím. Přesně tak funguje MOE – experti pracují paralelně, každý se věnuje specifické části problému a výsledky se poté skládají do komplexního výstupu.
Podle DeepSeek kombinace pokročilých algoritmů, frameworků a optimalizovaného hardwaru umožnila překonat klíčové komunikační bariéry mezi těmito expertními modely. Díky tomu systém dokáže škálovat na větší velikosti bez zbytečných dodatečných nákladů. Trénink modelu je navíc mnohem stabilnější a rychlejší, což umožňuje efektivněji využívat dostupné zdroje.
Post-tréninková optimalizace
Další klíčovou vlastností DeepSeek V3 je post-tréninková optimalizace pomocí syntetických dat generovaných modelem DeepSeek R1. Tento přístup zlepšil schopnosti modelu v oblasti logického uvažování a ověřování výsledků.
DeepSeek V3 si tak dokáže udržet vysokou přesnost nejen v běžných úkolech, ale i v komplexnějších testech, jako jsou matematické soutěže nebo řešení kódovacích problémů. Zajímavé je, že tento model výrazně těží z toho, že AI trénuje další AI. DeepSeek R1 generuje syntetická data, která se používají k dalšímu zlepšení schopností modelu DeepSeek V3. Tento přístup nejen zkracuje dobu tréninku, ale také dramaticky snižuje náklady a umožňuje efektivnější využití dostupných zdrojů.
Co to znamená pro budoucnost AI?
DeepSeek V3 je důkazem, že otevřené modely mohou konkurovat těm nejlepším uzavřeným AI systémům, a to za zlomek nákladů. Tento přístup nejenže podporuje rychlejší inovace, ale také otevírá dveře většímu počtu vývojářů a výzkumníků. Umožňuje tak rozšířit spektrum aplikací a výzkumu, které by jinak zůstaly nepřístupné kvůli finančním nebo technickým omezením.
Otázkou však zůstává, jaká bude reakce na tento trend. Regulace, jako jsou exportní omezení čipů, mohou sice zpomalit pokroky v určitých regionech, ale současný vývoj ukazuje, že inovace se těžko zastavují. Otevřené modely pravděpodobně přinesou zvýšenou konkurenci, což by mohlo motivovat firmy jako OpenAI, Meta nebo Anthropic k rychlejšímu vývoji a lepší dostupnosti jejich technologií.
Open-source komunita se tak vedle Mety rozšiřuje o dalšího velkého hráče a může hrát klíčovou roli v dalším směrování vývoje umělé inteligence.
Marek Bartoš
Další dnešní články








